![]()
| koi | win |
![]()
MOSIX: система управления кластером
Оглавление

1. Введение
MOSIX √ это программный модуль для поддержки кластерных вычислений на базе Linux [1]. Разработан в Hebrew University (Иерусалим). Существует семь UNIX-подобных версий MOSIX, из них версия дляLinux (на Intel-платформе)является последней. Достоинство MOSIX заключается в том, что он распространяется бесплатно
Прежде чем переходить к более детальному рассмотрению системы MOSIX, необходимо уяснить контекст, т.е. ее соотношение с такими распространенными пакетами как MPI и PVM.
Упомянутые выше пакеты обеспечивают исходное фиксированное размещение процессов по узлам кластера, в то время как MOSIX выполняет это динамически в зависимости от конфигурации доступных ресурсов. Пакеты MPI и PVM работают на пользовательском уровне (user level, иначе говоря, на уровне оболочки), т.е. на том уровне, на котором действуют обычные приложения. MOSIX функционирует как модуль ядра операционной системы, и потому является полностью прозрачным (transparent) для приложений.
Нет необходимости модифицировать приложения под MOSIX или связывать их с какими-либо библиотеками, и, уж тем более, распределять процессы по различным узлам √ MOSIX делает это автоматически.
MOSIX является масштабируемой системой. Число узлов в кластере университета Hebrew равно 100. Можно посмотреть фотографию(88Kb) этого довольно большого кластера.
Таким образом, MOSIX √ это, с одной стороны, альтернатива MPI и PVM, а с другой стороны, их развитие. Здесь необходимо отметить, что MOSIX и PVM (или MPI) могут работать одновременно на одном и том же кластере.
Тем не менее, главная цель MOSIX √ повысить общую производительность кластера путем более эффективного использования ресурсов.
Эффективное распределение ресурсов кластера √ является очень сложной научной проблемой, поскольку существует много различных видов ресурсов (например, CPU, память, I/O, средства межпроцессного взаимодействия (IPC)< и т.д.), использование ресурсов плохо прогнозируемо. Дополнительная сложность вытекает из того, что действия пользователей не координируются (т.е. они не согласованы).
В главных алгоритмах MOSIX, называемых алгоритмами разделения ресурсов (resource sharing algorithms, хотя, быть может, лучше перевести как ⌠распределения■, а не ⌠разделения■), можно выделить две части:
Все эти алгоритмы реализуются благодаря механизму миграции процессов (preemptive process migration √ PPM).
Необходимо еще раз отметить, что все указанные выше алгоритмы и механизмы реализованы на уровне ядра ОС и представляют собой загружаемые модули[2]. Как следствие, интерфейс ядра остается немодифицированным, а модули MOSIX √ прозрачными для приложений.
PPM может мигрировать нужный процесс, в нужное время и к нужному узлу. Обычно, миграция базируется на информации, предоставляемой алгоритмами разделения ресурсов. Однако, администратор может переопределить любые автоматические системные решения и мигрировать процессы вручную. Такая ручная (manual) миграция может оказаться полезной, например, при тестировании каких-либо новых алгоритмов распределения ресурсов.Отметим также, что администратор обладает такими дополнительными привилегиями, как право определять общую дисциплину работы или то, какие узлы будут доступны для миграции.
Каждый процесс имеет уникальный домашний узел (Unique Home-Node √ UHN), в котором он был создан. Обычно, таким узлом является входной (login) узел пользователя. Модель системного образа MOSIX заключается в том, что каждому процессу кажется будто он работает в своем UHN, при этом все процессы пользовательской сессии (users▓ session) разделяют окружение UHN. Процессы, которые мигрировали к другим (удаленным) узлам, используют соответствующие локальные ресурсы (т.е. ресурсы удаленного узла), но взаимодействуют с окружением UHN.
Поясним сказанное примером.
Предположим, что пользователь запустил несколько процессов, часть из которых мигрировали из UHN. Если пользователь, теперь, выполнит команду ps (в обычном случае выводит перечень запущенных на данном узле процессов с их характеристиками), то он увидит на дисплее информацию не только о тех процессах, которые выполняются на UHN, но и о тех, что мигрировали из UHN. Далее, если какой-то из мигрированных процессов прочитает текущее время, т.е. выполнит gettimeofday(), то он получит текущее время из своего UHN.
PPM является главным средством управления ресурсами. Пока требования к ресурсам со стороны приложения, таким, например, как CPU или основная память, остаются ниже определеной границы, соответствующие процессы находятся в UHN. Когда же эти требования превосходят границу, процессы начинают мигрировать к другим узлам, получая там недостающие им ресурсы. Главная цель миграции √ максимизировать производительность путем повышения эффективности использования общекластерных (cluster-wide) ресурсов.
Итак, единицей распределения работ в MOSIX является процесс. Пользователь может запускать параллельные приложения, инициируя множество процессов в одном узле, затем система распределит их по узлам кластера. Если в течение выполнения процессов станут доступными новые ресурсы, то алгоритмы разделения ресурсов установят этот факт, что в свою очередь приведет к перераспределению процессов.
MOSIX не предполагает наличие между узлами отношения подчиненности (master-slave)>: каждый узел может выполнять операции как автономная система, т.е. принимать решения независимо от других узлов. Это позволяет поддерживать динамическую конфигурацию кластера. Узлы могут присоединяться и выпадать из него с минимальным ущербом. По сути дела, это и означает, что кластер обладает свойством масштабируемости.
Децентрализованность (как следствие, и масштабируемость) достигается путем включения в алгоритмы стохастических элементов, при этом каждый узел основывает свои решения на знаниях о состоянии лишь некоторых других узлов и даже не пытается определить общее состояние кластера.
В качестве примера можно привести алгоритм стохастического рассеивания информации[3] (probabilistic information dissemination algorithm): каждый узел передает через постоянные интервалы времени информацию о своих доступных (свободных) ресурсах случайно выбранной подсистеме узлов кластера. В результате, в любой момент каждый узел имеет маленький буфер, называемый окном (window), с последней полученной (таким образом) информацией.
4. Алгоритмы разделения ресурсов
Как уже говорилось, среди основных алгоритмов разделения ресурсов MOSIX можно выделить алгоритмы:
Алгоритм динамического выравнивания загрузки (dynamic load-balancing) непрерывно пытается редуцировать разницу в загрузке между парой узлов, в результате чего, процессы мигрируют (при помощи соответствующего механизма) от более загруженного узла к менее загруженному. Эта схема является децентрализованной: редукция выполняется независимо для каждой пары узлов.
Количество процессоров в узле и их быстродействие является важным фактором в работе данного алгоритма.
Алгоритм предотвращения исчерпания памяти (memory ushering или depletion prevention) пытается разместить в ⌠оперативной памяти кластера■ (cluster-wide RAM) максимальное количество процессов, избегая при этом, по возможности, применения операций свопинга с диском[4]. Данный алгоритм срабатывает тогда, когда узел чрезмерно часто осуществляет свопирование по причине нехватки памяти. В таком случае, этот алгоритм переопределяет алгоритм миграции процессов, который отправляет процессы в узел, имеющий достаточно свободной памяти, даже если в результате миграции возникнет неравномерность загрузки.
MOSIX поддерживает прозрачную по отношению к приложениям миграцию процессов (preemptive process migration √ PPM).
После миграции процесс продолжает взаимодействовать с UHN, несмотря на свое расположение. Для реализации PPM мигрирующий процесс делится на два контекста (две части):
Пользоваетльский контекст, называемый удаленным (remote), содержит код, данные, стек и карты памяти. Удаленный контекст инкапсулирует в себе процесс, когда тот работает на пользовательском уровне (т.е. не в ядре).
Системный контекст, называемый наместником (deputy), содержит описание ресурсов, присоединенных к процессу, и стек ядра (kernel-stack) для выполнения системного кода от имени процесса. Наместник инкапсулирует процесс, когда тот выполняется в режиме ядра. Наместник является платформо-зависимой частью процесса, следовательно должен оставаться в UHN.
Итак, хотя процесс может мигрировать много раз между различными узлами, его наместник всегда остается в UHN.
Интерфейс между наместником и удаленным контекстом достаточно четко определяется. Поэтому есть возможность расчленить взаимодействие между этими контекстами и реализовать его через сеть. Это делается на т.н. уровне связи (link layer) при помощи специального коммуникационного канала. Следующий рисунок иллюстрирует выше сказанное.
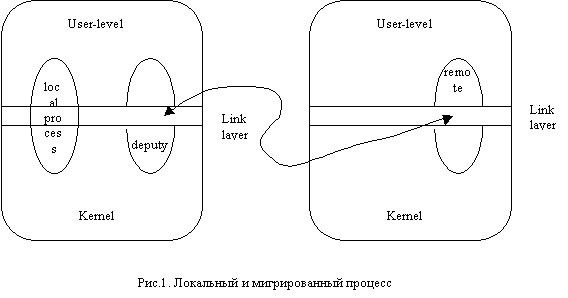
На рисунке изображены два процесса, которые разделяют UHN. Процесс слева является обычным Linux-процессом, в то время как процесс справа √ разделенным на мигрировавшую удаленную часть и наместника.
Время миграции состоит из двух компонент:
Взаимодействие между процессами может осуществляться через интерфейс системных вызовов. Все системные вызовы, которые выполняются процессом, проходят через уровень связи удаленного узла. При этом, если системный вызов является платформо-независимым, он выполняется на удаленном узле локально. В противном случае, системный вызов передается к наместнику, который выполняет его в UHN от имени соответствующего процесса. Далее, наместник возвращает результат назад в удаленный узел.
Очевидным недостатком такого подхода являются большие накладные расходы (overhead) при выполнении системных вызовов. Дополнительные издержки появляются при выполнении операций сетевого доступа. Например, все сокеты создаются в UHN, это приводит к большим коммуникационным затратам если процесс мигрирует из UHN. Для решения этой проблемы были созданы т.н. мигрирующие сокеты, которые передвигаются вместе с процессом и, таким образом, позволяют утановить прямую связь.
Накладные расходы могут быть значительно снижены, если первоначальное распределение взаимодействующих через сеть процессов осуществить при помощи PVM или MPI. После чего, когда загрузка узлов кластера разбалансируется, соответствующие алгоритмы MOSIX выполнят перераспределение процессов для повышения производительности[5].
В заключение необходимо отметить, что некоторые функции Linux не совместимы с разделением процесса на два контекста. В таких случаях, соответствующий процесс автоматически запирается в UHN.
 Web master
Web master
{kind=link}