 OO Concept: Inheritance
OO Concept: Inheritance
OO Concept: Inheritance
OO Concept: Inheritance
class Track {
public:
// Constructors and Destructors
Track(Float_t mass, Float_t energy);>
Track::Track();
~Track();
// Getters and Setters
Float_t GetEnergy();
void SetEnergy( Float_t energy);
private:
// Data
Float_t fEnergy;
Float_t fMass;
Float_t fMomentum;
};
it really doesn't do very much but further features can slowly be added.
Already we have an example of the evolution of simple systems although here
this isn't special to OO; good procedural design starts with simple procedures
that evolve with time. As we add code to our Track class we will reach a
point where we have to deal in specifics: Is the track charged or neutral,
massive or massless etc. Suppose our Track object is part of a Monte Carlo
and we want to add the Propagate member function which
is supposed to transport the track.
Such a function will be a strong function of particle type so
quickly this function would start to have
conditional code depending on particle
type. This is a sure sign that something is wrong with the model
(or abstraction).
What has happened is we are no longer dealing with a single concept of a generic track, but are instead dealing with a set of more specific tracks. Instead of proceeding, we need to define new classes that again have a simple model. For example we could decide, as the first level of specialisation, to have two classes: NeutralTrack and ChargedTrack. The problem is that, although different, they do have some features in common. As previously mentioned, one the basic OO principles is Don't solve the same problem twice. So we need two separate classes and yet require them to share common features. This is where inheritance comes to the rescue. It allows us to define new classes that build on existing ones. To make a start we could define a ChargedTrack class like this:-
class ChargedTrack: public Track {
};
This says that ChargedTrack inherits from Track. As written, ChargedTrack
objects are functionally identical to Track objects; they have the
same
data members
and
member functions.
Before we start to differentiate ChargedTrack lets look how inheritance is
specified. The colon after ChargedTrack
indicates that a list of one or more classes follows. When one class inherits
from another, it is called a
subclass
and the class it inherits from is called a
base class.
C++ allows one class to inherit from multiple base classes but this is not
universal in OO; Java for one only allows one base class. The relationship
between a subclass and a base class is sometimes referred to as an
IsA
relationship. We can say: A ChargedTrack IsA Track.
You should recognise the access specifier public from the OO topic Private & Public. It determines how the base class member access is modified. Why should we want to be able to change that? Suppose, for some good reason that escapes me for the moment, the designer of the base class decided to make all the data members public. Now we want to use the class but want to block up that security loop-hole. If we had put:-
class ChargedTrack: private Track {
};
then all the Track members would be private in our class. Of course, as we
designed the Track class we know that we don't have a security problem, we
kept all sensitive members private. Actually this is a problem as it
means that inherited classes can access them either! Now there may be good
reasons for that, but generally classes do allow subclasses access by using a
third type of protection: protected, which permits
that but still keeps the user from touching them. The access specifiers
form a 3 level system:-
Returning to our Track class, we can now start work on the Propagate member function. As the concept of propagation is generic, i.e. not specific to either charged or neutral tracks, it follows that our Track class should have a Propagate member function. But what should it do? Should it assume charged tracks, or neutral tracks or neither? One approach is to say it does whatever we consider to be the more generic, and that we consider neutral tracks more generic. If this seems unreasonably arbitrary, an alternative solution will be explored in the OO topic Interfaces & Abstract Classes. Working to this plan, a partial declaration of our 3 classes would be:-
class Track {
public:
void Propagate();
...
};
class ChargedTrack: public Track {
public:
void Propagate();
...
};
class NeutralTrack: public Track {
...
};
If we now create a charged and neutral track and subsequently send them the
Propagate message:-
ChargedTrack *MyChargedTrack = new ChargedTrack(0.938, 1.0); NeutralTrack *MyNeutralTrack = new NeutralTrack(0.935, 1.0); ... MyChargedTrack->Propagate(); MyNeutralTrack->Propagate();Then, the charged track message will be dealt with by ChargedTrack::Propagate (i.e. the Propagate defined in class ChargedTrack). Its another example of function name reuse or overloading. The ChargedTrack class has a Propagate member function so that must be the function to be called. On the other hand NeutralTrack has no such member function but inherits one from Track, so neutral track propagation is handled by Track::Propagate.
As the code develops, the ChargedTrack and NeutralTrack classes will diverge. Each can have new data members and member functions and each can decide what parts of the Track member functions to modify and what to inherit unchanged.
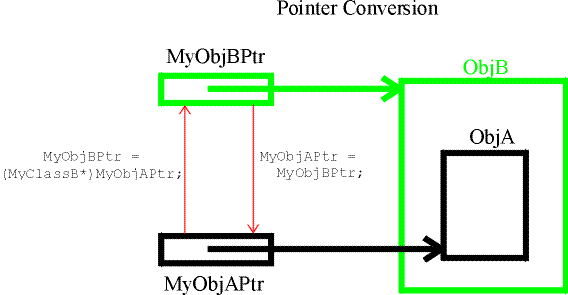
When class B inherits from class A then objects of class B have embedded objects of class A. Given the inheritance tree the compiler knows how to convert pointers between A and B. Given a pointer to a class B object, C++ allows it to be converted to a class A pointer simply by assignment. For example:-
ChargedTrack *MyChargedTrack = new ChargedTrack(0.938, 1.0);
Track *MyTrack = MyChargedTrack;
Having got a
pointer to the base class object it can then be sent messages as if
it were an independent object. How it behaves depends on whether it "knows"
its embedded, which is the subject of the OO topic
Virtual Functions &
Polymorphism.
The compiler will permit pointer conversion in the opposite direction, from A back to B, although the conversion must use an explicit type cast:-
MyChargedTrack = (ChargedTrack*) MyTrack;This is an unsafe conversion. Although the compiler knows how to adjust the pointer it makes no attempt to confirm that the object A is indeed embedded inside B, only that it could be. It trusts the user to know what they are doing. Get it wrong and a corrupt pointer results, and what ensues will not be pleasant!
Internally object B can send messages to A by directly using member functions. So, within some ChargedTrack member function we could code:-
energy = GetEnergy();
which uses Track::SetEnergy. Of course, for a ChargedTrack object:-
Propagate();would be handled by ChargedTrack::Propagate as it has overloaded the function. However, it can still access Track::Propagate simply by:-
Track::Propagate();So not only can an inherited class leave a member function unchanged, as the NeutralTrack did for Propagate, or replace it, as ChargedTrack did, it also has the choice to augment it by calling it and adding additional functionality.
Track::Track(Float_t mass, Float_t energy): fMass(mass) {
SetEnergy(energy);
}
which initialises fMass with the value mass and calls SetEnergy to define
fEnergy and fMomentum. In the case of inheritance, the
constructors of all the base classes are called before the class's constructor
executes. So a constructor can send messages off to its base class
objects safe in the knowledge that they have already been properly initialised.
But what constructors will C++ choose for the base classes? By default it
will chose the .. err, well default. However this is where the initialiser
construction is very useful. For our ChargedTrack, we could define a
constructor like this:-
ChargedTrack::ChargedTrack(Float_t mass, Float_t energy): Track(mass,energy) {
...
}
The initialising of members can include the embedded base class objects, so we
have complete control, for each constructor, of which base class constructors
get used.